GIT Workflow¶
GIT Version Control System¶
GIT is a free and open source distributed Version Control System (VCS) designed to handle everything from small to very large projects with speed and efficiency. The main difference between GIT and tools like Subversion (SVN) and CVS (obsolete since 2008) is that GIT is a distributed VCS while SVN and CVS are centralized. Distributed systems ensure that an entire project will not be disrupted if a single node loses functionality since all the machines have a functional copy of the centralized repository. This means that each local machine has an entire copy of the whole project, meaning that they can work internally without communicating with the server to stage changes.
This can be illustrated with the following figureure:
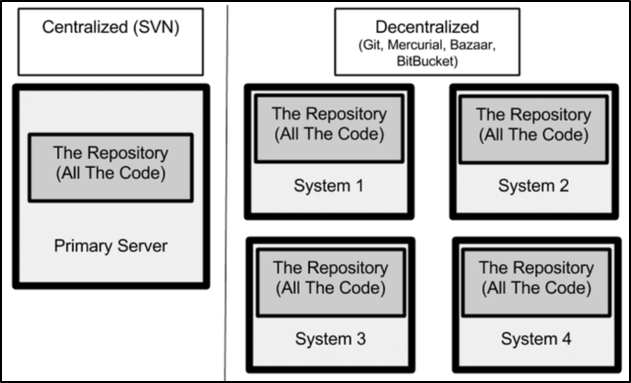
Figure 1 CVS and DVCS
Distributed Versioning Control Systems allow users to work internally and realize commits without the need to push the changes to their server repository. When it comes to collaboration in DVCS merging, branching and resolving conflicts is fast and smooth.
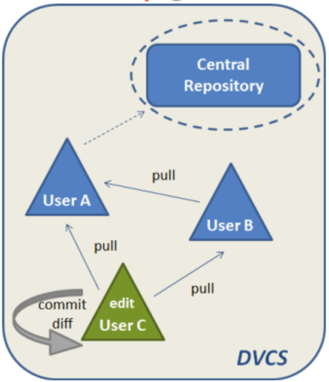
Figure 2 Distributed VCS
Branching¶
GIT allows multiple users to work in collaboration. When it comes to large projects with parallel development, it is very important to have a clear structure allowing each team member to work individually without polluting other teams’ work. GIT’s approach for this issue is called “branching”. Branches are usually created to work on specific projects or features, and once the development is over branches are merged back into the main branch. This way the master branch will only contain the final commits from the development branches.
Three main branches will define our project. These branches will be time-infinite and will not be closed:
- The master branch will contain the project’s final stable releases. This branch will hold the validated published STEP releases.
- The development branch holds the result of development validated by the developer teams. To commit in this branch, development teams need to create merge requests to be accepted by the upstream repository administrator (this will be presented in the FORKING section).
- The release branch virtually locks the development process for a specified release, meaning that no additional features will be developed for that specific release. The main goal of this branch is to provide last minute integration & bug fixes between the validated development and the master branch.
The main structure is presented with the Figure 3 and Figure 4
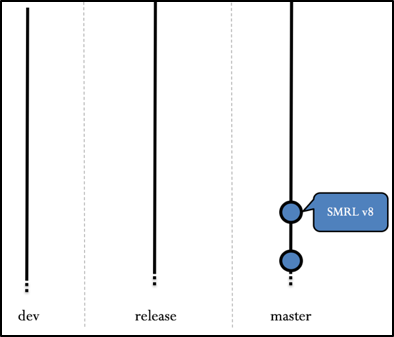
Figure 3 Main core branches
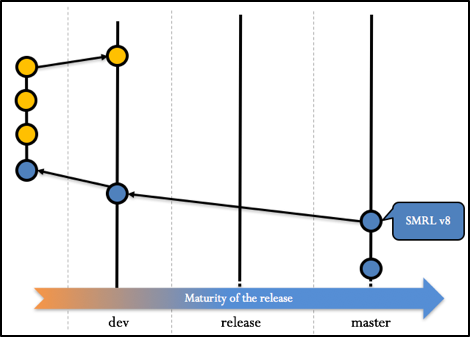
Figure 4 Branches and features
Each project will be represented by a branch created in the forked repositories of each team and merged back to the dev branch. This means that each team will create a branch for the project they are working on. This means that if a team is working on 2 projects simultaneously, it is mandatory to open a branch for each project.
Whenever the development of each team is validated and merged back into the dev branch there will be a checkout to the release branch. This means that no additional features will be added to that specific project release. In the release branch, last minute bug-fixes and integration will occur. Whenever a bug-fix is committed into the release branch, it must be merged into the development branch to take the bug-fix in consideration.
Once a final and stable release of the project is ready to be published, the release branch is merged back into the master branch. The scenario described previously can be represented by the following figureure, where 2 teams have been working simultaneously on 3 different features producing a final release called “SMRL v10”:
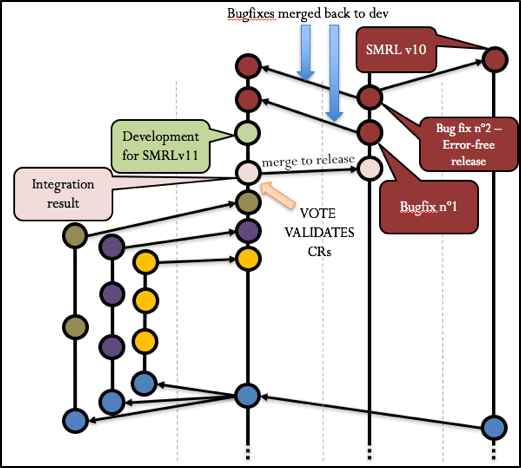
Figure 5 Complete scenario
Note
The following scenario implies that teams need to synchronize with the upstream repository before creating a merge request. That way conflicts are avoided and the merge request process will be faster.
This branching system allows us to benefit of these main features:
- Branches are freely managed by the developers in local machines
- Allows parallel development without polluting the master branch
- Rapid iteration cycles into the repository
- Gives control over when and where the commits are made
Forking¶
Now that the GIT workflow has been defined, other points need to be defined. Since GIT is a Distributed Versioning Control System, each team will have locally the complete working repository. In a low-level approach, this means that each developer will have in their local machine the complete repository. This implies that for a new developer to access the main repository, a new user should be created and his access rights granted. Since multiple teams will work simultaneously, user management should be done by the team leaders. Having to manage each user individually is not interesting and should be avoided in the main repository. This situation is experienced by large open-source projects where users wish to access and develop features for the project. A GIT solution for this situation is called FORKING.
Basically, a fork is a copy of a repository. Forking a repository allows teams to freely experiment with changes without affecting the original project. Most commonly, forks are used to propose changes to someone else’s project without impacting the main project with their personal work. Therefore, repository administrators don’t need to manage user access to the upstream repository.
Therefore, each team will have their own forked repository in which they will develop the new features. This allows each team to work with their custom procedures and handle their own project access rights.
The following figureure illustrates the concept where the STEPlib repository is the upstream repository and teams need to work on two change requests.
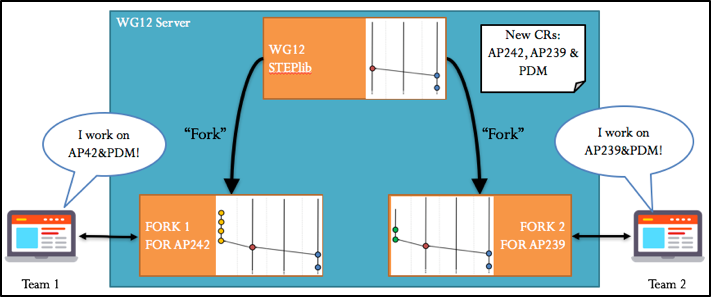
Figure 6 Forking structure
A couple of points can be extracted from this figureure:
- Only the team administrators will fork the project, meaning that access to the upstream repository will only be given to a few users.
- Each team administrator is responsible and free to manage their forked repository and the users who can access it.
- Branches to develop new features are created in the forked repositories. The upstream repository will only have the master, release and development branches.
As mentioned in the branching section, branches represent a project that is being developed currently and therefore are created in the forks. This means that whenever changes are ready to be pushed back to the upstream repository, a merge request must be created. However, teams can also synchronize their branches and work together without the need to merge changes to the upstream repository. Therefore, the procedure for a team to import the current work of another team is simple and will be explained later.
Once a merge request is sent, the administrator from the upstream repository will be able to preview the changes that have been made and is free to accept them or discard them. If the changes are accepted, the merge request will be realized between the forked branches and the development branch.
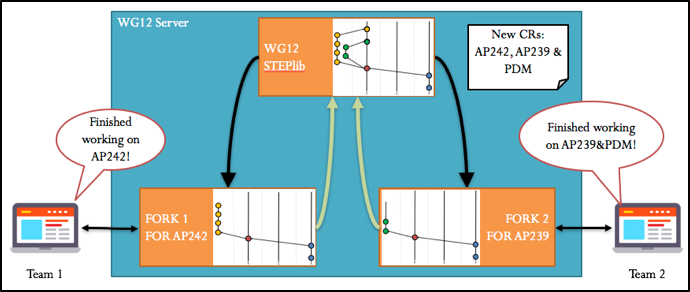
Figure 7 Merge request
As it can be seen in the figureure above, the upstream repository will be able to import the commits from the development branches, keeping in the development branches only the last commit that will appear as a merge request as seen here:
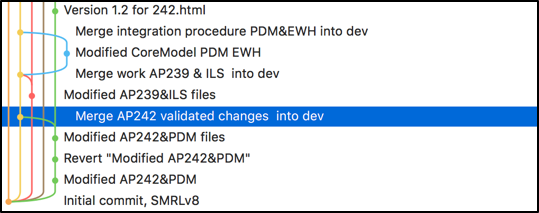
Figure 8 Merge example
Working scenario¶
In the following section, we will apply this git workflow to an example project. In this project, we wish to develop a new stable SMRL version. To do so, Change Requests are defined and consist on updating the AP239, the AP242 and the PDM. Two teams will be working in this project and therefore two forks will be created:
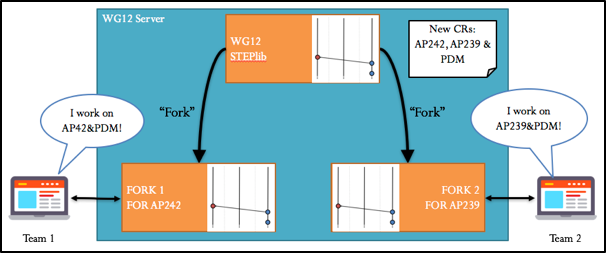
Figure 9 Fork creation
Now that each team have created their fork, they will create a branch for each CR they will be working on. Once their development process is complete, they will create a merge request to merge their changes into the development branch of the upstream repository.
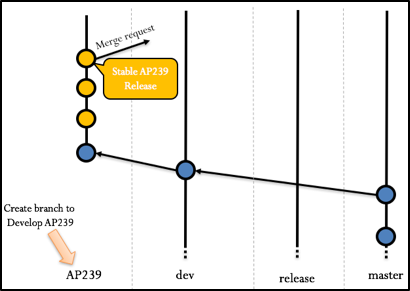
Figure 10 Merge request between the AP239 branch and the upstream development branch
At this point we suppose that changes have been made by both teams and merge requests have been submitted and accepted into the upstream repository. The story of the upstream repository should look like this:
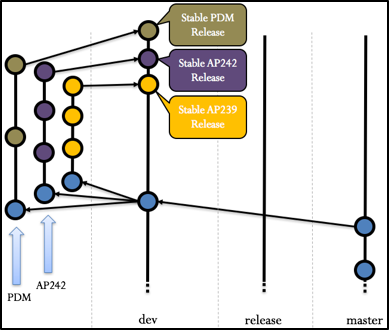
Figure 11 Upstream repository story
Both teams will need to pull the new development branch to be able to test if the different commits work well together. At this point an integration result is produced fixing eventually some points.
At this point the team will vote and validate the development results by the Change Requests. A checkout to the release branch will be made where last minute bug-fixes will be made before the release. This means that no more new features will be produced for that specific release. However, development of new features for future releases can still occur in parallel in the development branch (this can be seen in figureure 12). Therefore, whenever a release is locked for release, development is not interrupted allowing teams to focus on producing future content.
Whenever a bug-fix is produced in the release branch, it should be merged back to the development branch allowing developer teams to work with the latest code (figureure 12 illustrates this with the bug-fix nº1). Once a stable release is produced, it will be merged into the development branch and into the master branch.
This scenario is represented in the following figureure:
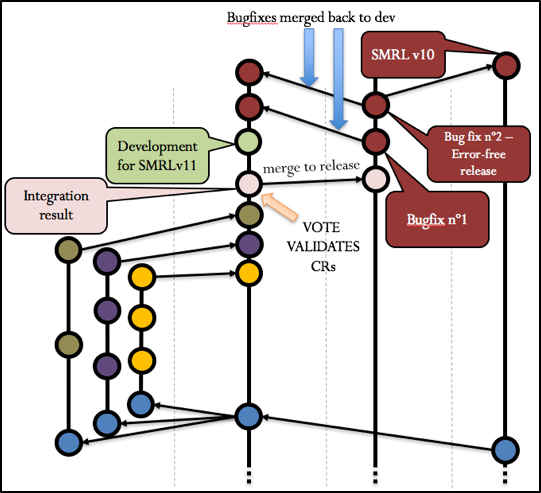
Figure 12 Complete scenario for development of SMRLv10
This simple example aims to illustrate the GIT workflow applied to a concrete example which is the development of the SMRLv10. We can see that the fork procedure allows teams to work freely on their Change Requests. We can also see that this concept grants the upstream repository administrator a precise control of what is being merged and in which branch.
This branching structure will first allow us to keep a clean master branch containing only final stable releases of the project. In addition to that point, the release and development branches structure allows teams to start developing new features in parallel while the release of a current version is currently happening.